Final Report
1 Introduction & Background
Credit card fraud is an increasing problem around the globe. Financial Fraud Action UK, for example, a trade association for UK financial services reported that losses from fraud totaled 618 million pounds which is a 9% increase from the year before. Additionally, this contributed to the fifth consecutive year of increased credit card fraud.
Credit card fraud detection is an active area of research: existing analyses of credit card fraud have included techniques including deep learning, correlation matrices, and confusion matrices. We noted some potential complexities to credit card fraud data from our literature review: few fraudulent entries, no null values, and high false positive or high false negative rate.
2 Problem Definition
According to Experian, credit card CVV’s sell on the dark web for as little as $5 and include personal information such as name, Social Security number, date of birth, and complete account numbers.In the digital age, it is important to have sophisticated fraud detection techniques to protect people’s livelihoods. Our project focuses on the detection of credit card fraud, to identify, analyze, and prevent financial fraud.
3 Dataset
We found a Kaggle dataset to suit our purpose, titled Credit Card Fraud Detection. It contains anonymized credit card transactions from September 2013 collected from European cardholders by the University of Brusells and the Machine Learning Group. The data is labeled as either fraudulent or genuine and is highly unbalanced, as the positive class/frauds account for 0.172% of all transactions with a total of 284,807 transactions.
4 Methods
Our dataset is complete, so minimal cleaning is required. Because the dataset is very imbalanced, we have chosen to use the data preprocessing technique of oversampling on fraudulent transactions.
We plan to implement and analyze fraud detection results for GMM clustering, logistic regression analysis, and a multi-layer perceptron neural network (MLP). GMM results in a soft-clustering output that we can compare against the dataset’s labeled output to determine the model’s accuracy. Regression analysis (in our case, logistic regression) can be used to identify the correlation between the input parameters and fraudulence. We can implement MLP in the form of a feed forward network that spits out a binary classification result. It would have (at least) three layers: an input layer entailing the feature vectors of our data points, the hidden layer(s) containing the weights (that are propagated to the next layer if any), and the final layer containing the predicted classification.
4.1 Data Cleaning
We didn’t have to run extensive cleaning since all our entries were complete and in good form. This is with the exception of minor changes such as eliminating newline characters to not interfere with the values. We split our dataset into “data” as floats and “labels” as integers.
4.2 Data Preprocessing
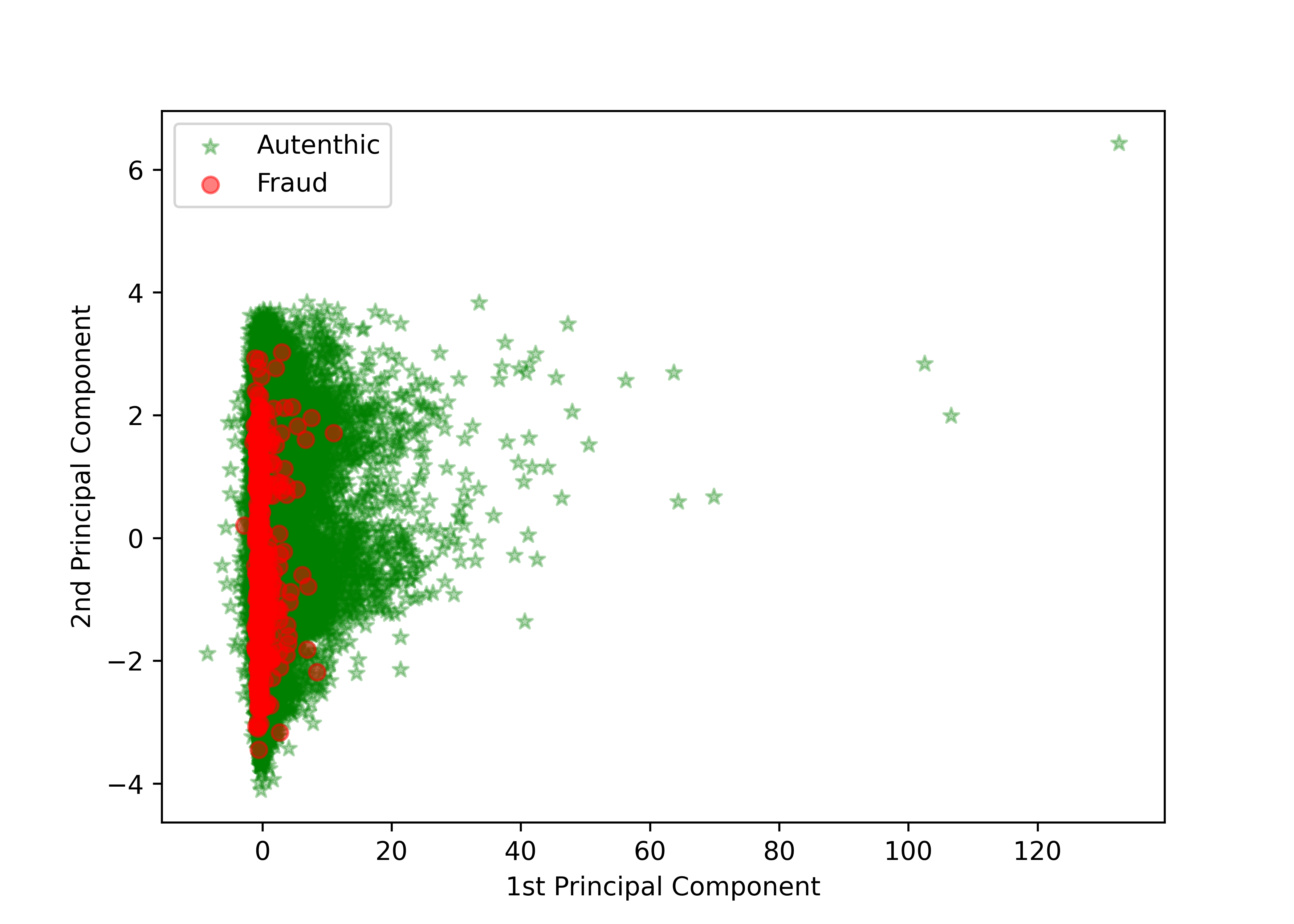
PCA is one of the most prominent pre-processing methods to improve classifier performance. Our dataset had already been run through PCA and contained 28 numerical input variables which were the result of this PCA transformation.
We scaled this data using StandardScaler from the sklearn.preprocessing library and split our data and labels into training and test at a 80:20 split.
For cross validation, we employed StratifiedShuffleSplit from sklearn.model_selection for splitting instead of a regular unbiased split. This cross validation method combines k-fold and shuffling techniques to maintain the percentage of majority and minority samples across folds.
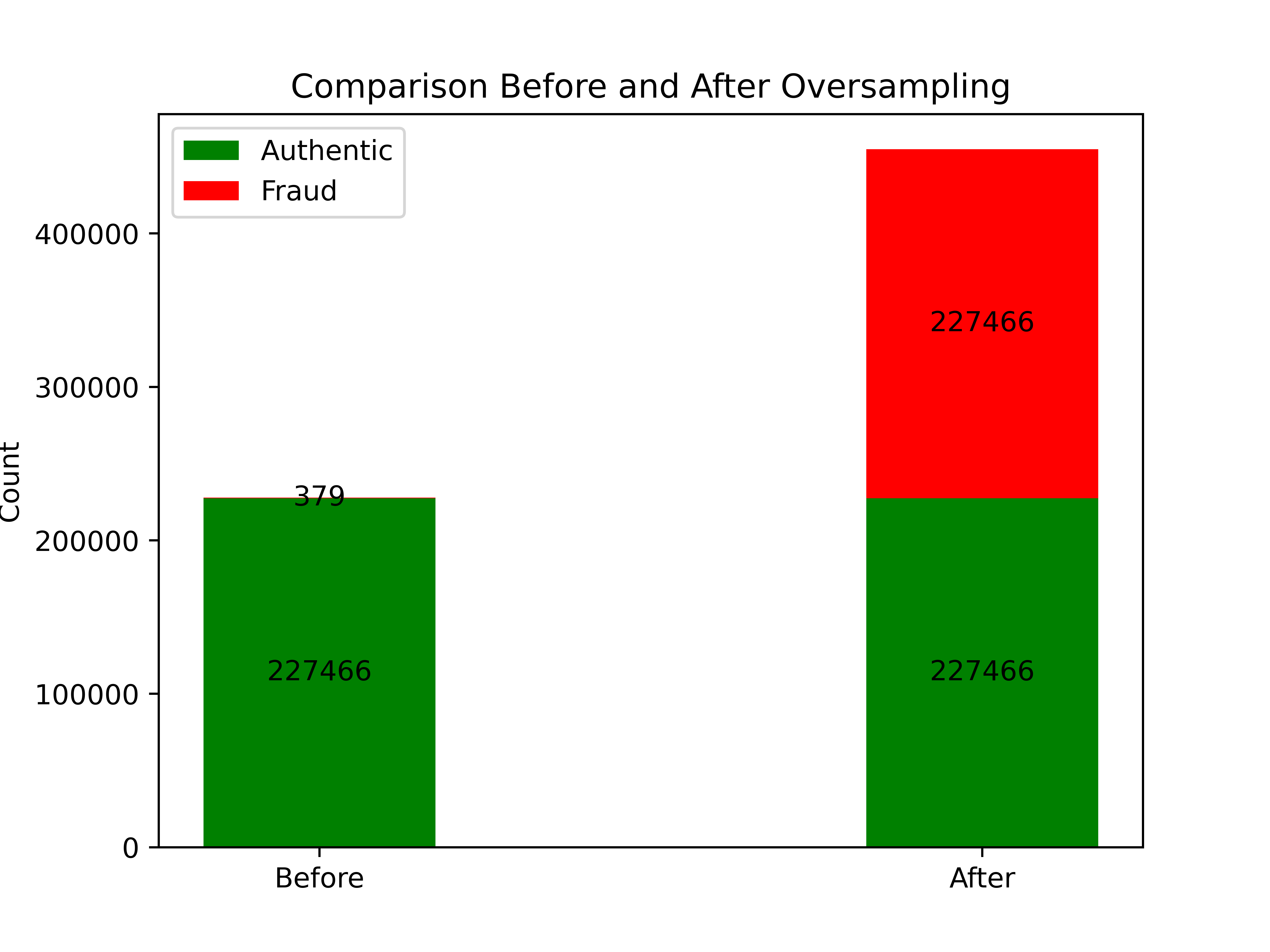
Our data reflects a majority: minority ratio of 227451: 394. For resampling techniques, we chose oversampling since we wanted to equalize this majority: minority ratio without losing a lot of data. For oversampling, we used the popular SMOTE (Synthetic Minority Oversampling Technique) library that is widely used for resampling highly unbalanced datasets. As the name suggests, this technique generates synthetic data by interpolating samples from the minority class using nearest neighbors.
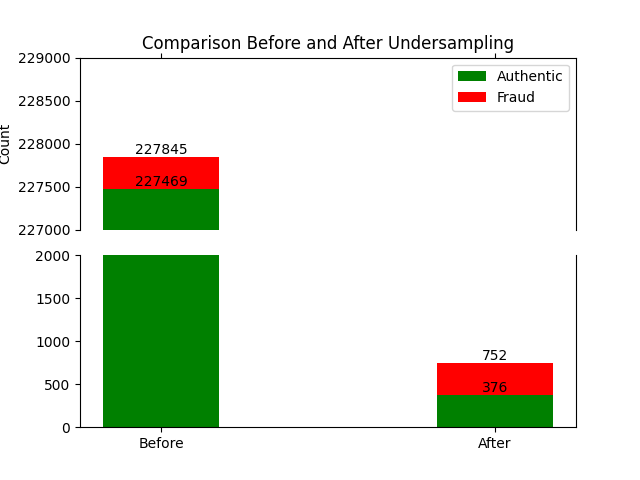
We also tried employing a combination of undersampling and oversampling to balance the distortion caused in minority class if we overpopulated it too far. For this we used RandomUnderSampler from the imblearn undersampling library.
4.3 Logistic Regression:
We chose to implement logistic regression since it is a relatively straightforward but effective classification technique that is easy to interpret, analyze and debug. Additionally, a supervised method utilizes all the known information and provides a good first glance into our dataset. Logistic regression is also widely used and well suited for the task of binary classification which aligns with our problem definition of predicting whether a transaction is fraudulent or not.
We employed LinearRegression from the sklearn.linear_model library to implement this method. Additionally, for an extra layer of verification, we implemented cross validation from sklearn.model_selection and paired it with our resampling techniques (SMOTE and random undersampling) in order to find the best combination.
4.4 Random Forest:
We chose to implement Random Forest due to its utility in binary classification problems, especially when dealing with a large dataset. As stated before, utilizing another supervised method is well-advised with a labeled dataset such as ours.
We used RandomForestClassifier from the sklearn.ensemble library for this method. We also utilized SMOTE undersampling in order to account for our imbalanced dataset.
4.5 Neural Network:
We chose to attempt implementing a Neural Network for this problem in order to find a high accuracy predictor of credit card fraud. We used an MLP Neural Nework with an input layer of 30, three hidden layers of sizes 50, 200, 200 and 50, with an output layer giving us the prediction for any given datapoint.
We tuned the hyperparameters of the neural network with sklearn’s GridSearchCV, which performs an exhaustive search over the input hyperparameters. We tested the network with hidden layers of sizes (50,200,50), (150,100,50), (120,80,40), (100,50,30), and (50, 200, 200, 50) and found that the largest and deepest network outperformed the smaller ones. We suspect the complexity of the network enabled better feature analysis of the 30 input dimensions.
4.6 SVM:
The support vector machine algorithm (SVM) is incredibly useful when working with datasets with many features, such as ours. This algorithm generally works well without needing to do a lot of transformations on our dataset. SVM is typically very successful in application areas ranging from image retrieval, handwriting recognition to text classification. However, when faced with imbalanced datasets where the number of negative instances far outnumbers the positive, the performance of SVM drops significantly. Classifiers generally perform poorly on imbalanced datasets because they are designed to generalize from sample data and output the simplest hypothesis that best fits the data, based on the principle of Occam’s razor. Hence, we didn’t anticipate a high recall or precision and took some time optimizing the implementations and tuning the parameters. Another downside is that this algorithm can take a long time to run with a dataset as large as this one instances.
We used the linear_model library in sklearn in order to implement SVM. We implemented a linear SVM using a Stochastic Gradient Descent Classifier with loss function as ‘hinge’. We put this through a pipeline, along with standard scaling and fit it using undersampled training data with SMOTE.
5 Results
Since our data is highly unbalanced, we cannot rely on just precision to discern how effective our model is. Using the terminology of positives, negatives, false and true, we define positives to be fraudulent transactions and negatives to be non-fraudulent, and true to be aligned with the ground truth and vice versa. For example, if our model predicts a non-fraudulent transaction to be fraudulent, it is considered a false positive.
Our data contains ~99.828% non-fraudulent cases and 0.172% fraudulent cases. If we just use accuracy, a model that always predicts “non-fraudulent” will achieve an accuracy of 99.828%. Out of context, this is a terrific accuracy, but we know that the model knows nothing about the dataset. This is because we are only looking at the true negatives vs total number of negatives. Looking at the same ratio but for positives (also defined as recall below), this model will attain 0% because it never classifies anything as fraud.
Hence, for an unbalanced dataset, accuracy doesn’t tell us everything about how well the model fits our dataset; we must consider other performance metrics that measure other ratios involving true negatives, true positives, etc.
For our analysis, we use recall, area under ROC curve (AUC-ROC), and accuracy as our performance metrics. Recall is defined as the ratio between the number of correctly identified positive samples and total number of samples classified as positive samples(this number would include the false positive samples). Accordingly, the higher the metric, the higher ability of the model to detect positive samples.
AUC-ROC, overall, tells us how well the model can distinguish between classes on a normalized scale between 0 and 1. A higher number tells us the model is better at making this distinction. AUC-ROC is composed of two separate components: Area Under the Curve and Receiver Operating Characteristics. Area Under The Curve(AUC) is a measure of separability. Receiver Operating Characteristics(ROC) functions as a probability curve showing the performance of the classification model at all classification thresholds.
5.1 Logistic Regression:
Our logistic regression model appears to produce the best results when paired with SMOTE undersampling techniques. For our dataset, recall is incredibly important as it quantifies the proportion of fraudulent transactions that were detected. Logistic Regression with SMOTE produced the highest recall and AUC-ROC scores, while also maintaining an accuracy score of above 99%. For all instances of logistic regression, precision was relatively low, meaning we had a relatively high rate of false positives (authentic transactions being labeled as fraudulent).
5.1.1 Logistic Regression, no preprocessing:
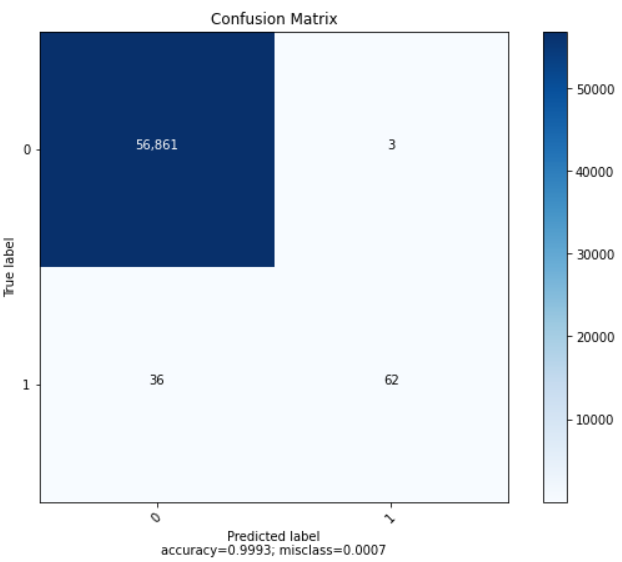
| Accuracy | Recall | Precision | AUC-ROC |
|---|---|---|---|
| 0.999315 | 0.816300 | 0.854096 | 0.816300 |
Without pre-processing, we appeared to produce the highest precision scores of all the logistic regression models we ran, however this simultaneously produced the lowest recall - which is far more undesirable in the context of our dataset.
5.1.2 Logistic Regression, with CV:
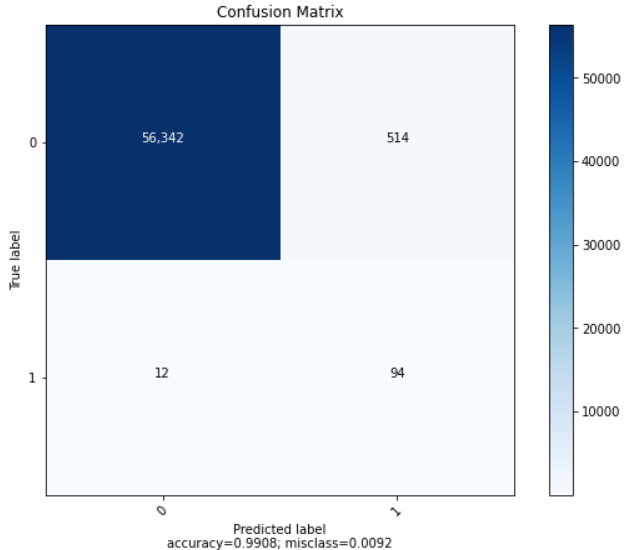
| Accuracy | Recall | Precision | AUC-ROC |
|---|---|---|---|
| 0.999069 | 0.938876 | 0.740027 | 0.938876 |
5.1.3 Logistic Regression, with SMOTE:
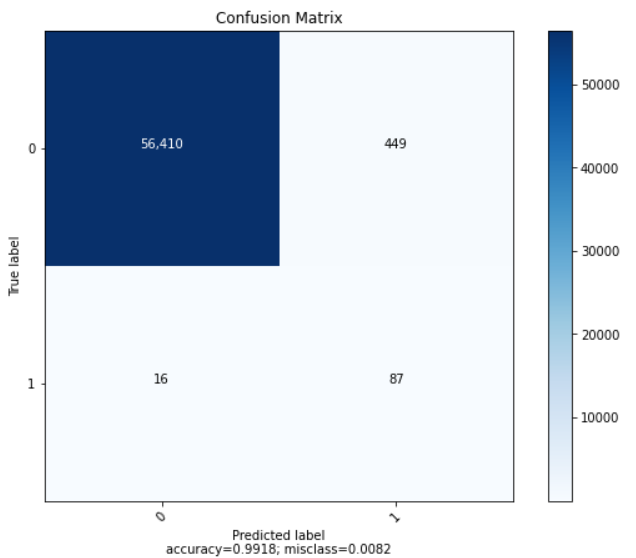
| Accuracy | Recall | Precision | AUC-ROC |
|---|---|---|---|
| 0.991170 | 0.965630 | 0.771072 | 0.965630 |
5.1.4 Logistic Regression with CV and SMOTE:
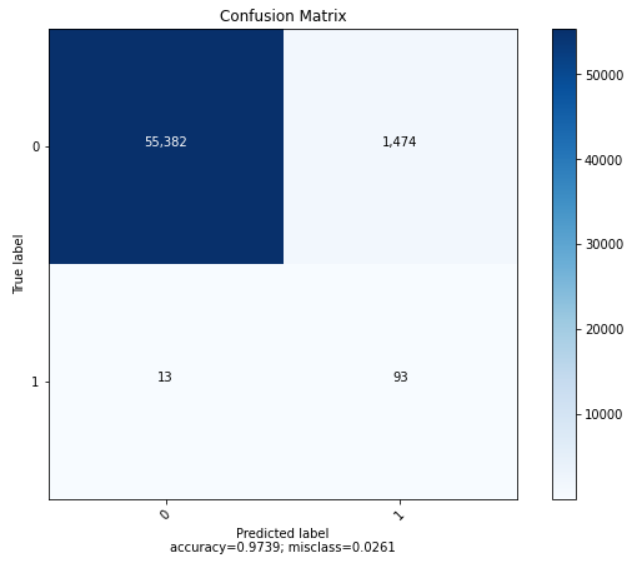
| Accuracy | Recall | Precision | AUC-ROC |
|---|---|---|---|
| 0.991837 | 0.918382 | 0.727601 | 0.918382 |
5.1.5 Logistic Regression with Undersampling:
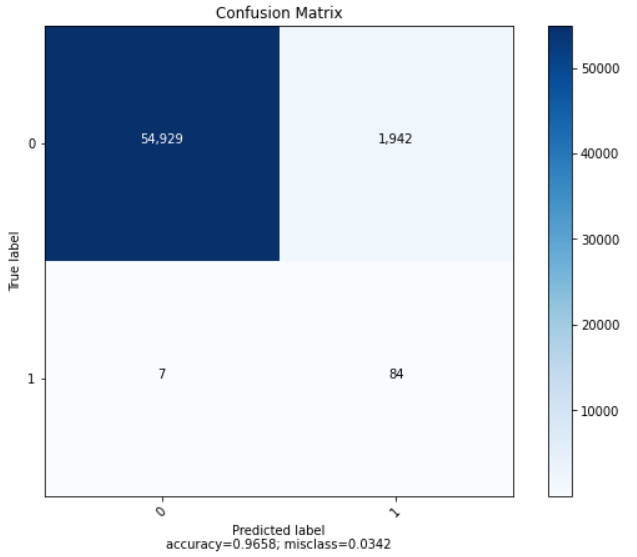
| Accuracy | Recall | Precision | AUC-ROC |
|---|---|---|---|
| 0.973895 | 0.925717 | 0.466111 | 0.925717 |
5.1.6 Logistic Regression with Undersampling and CV:
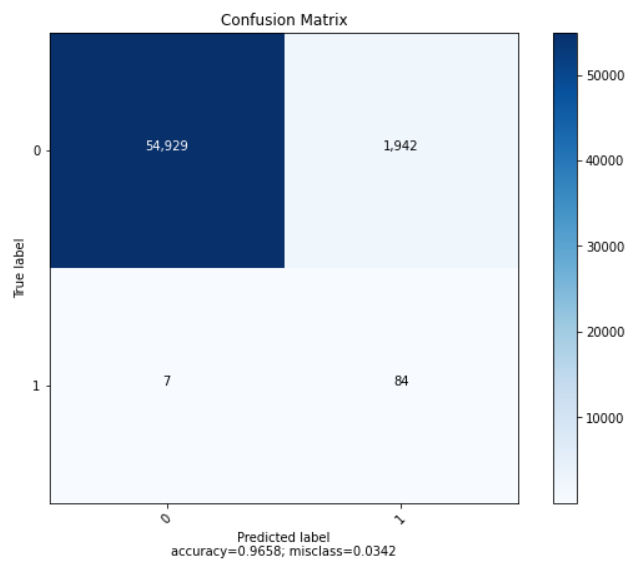
| Accuracy | Recall | Precision | AUC-ROC |
|---|---|---|---|
| 0.965784 | 0.944465 | 0.677143 | 0.944465 |
5.2 Random Forest
Our Random Forest model produced a decent recall score - though not nearly as good as with linear regression - while maintaining an accuracy score of well over 99%. The high AUC-ROC score indicates that our model distinguishes well between the two classes - those being fraudulent and authentic transactions.
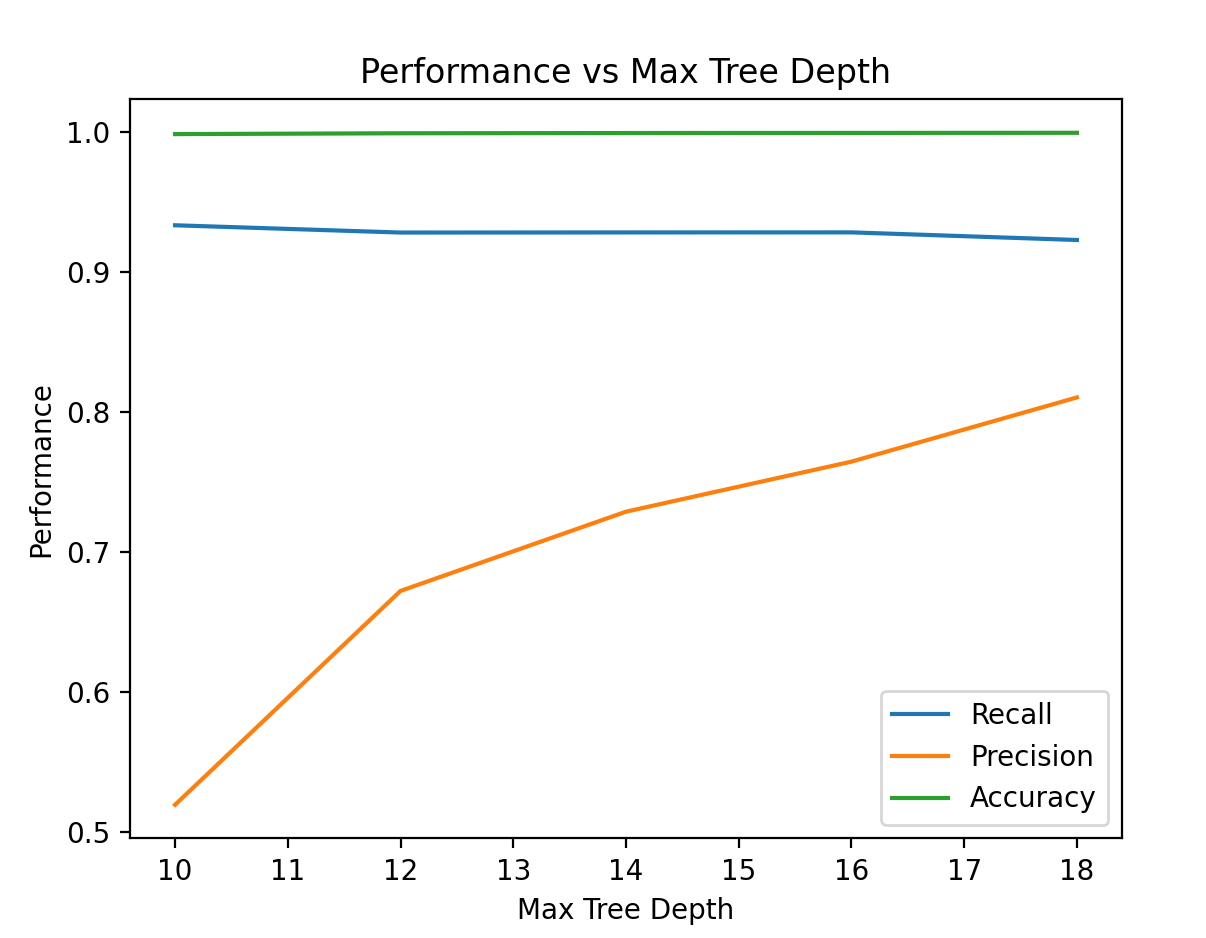
We also tuned the depth of the tree. Analysis revealed that the performance of the random forest increased with depth, likely because the greater depth allowed better analysis of the high-dimensional data. When the max depth exceeded 20 features, training time exceeded 10 minutes, and further turning became difficult. With greater computer power, we would continue analysis until increasing the max depth decreased performance.
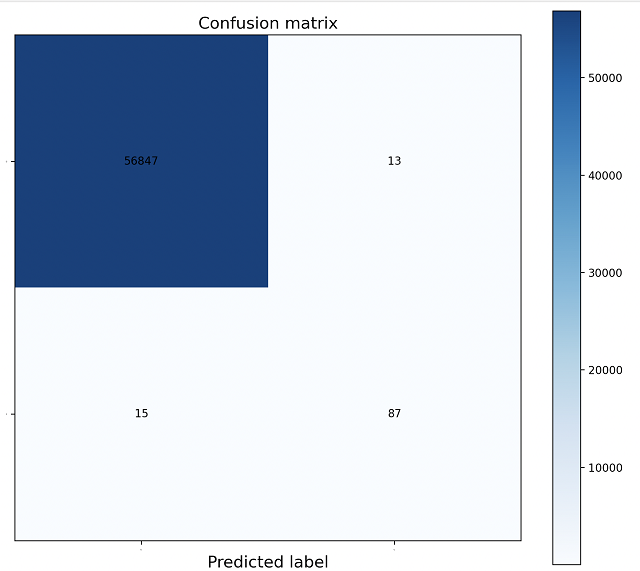
| Accuracy | Recall | Precision | AUC-ROC |
|---|---|---|---|
| 0.999508 | 0.852941 | 0.870000 | 0.918129 |
5.3 MLP Neural Network
After tuning with the hidden layer sizes, our MLP Neural Network produced a recall of over 83% - most of the fraudulent transactions were properly labeled - while still having an accuracy score of around over 99%. The precision score is pretty decent with about 87% of the transactions labeled as fraudulent were in-fact fraudulent.
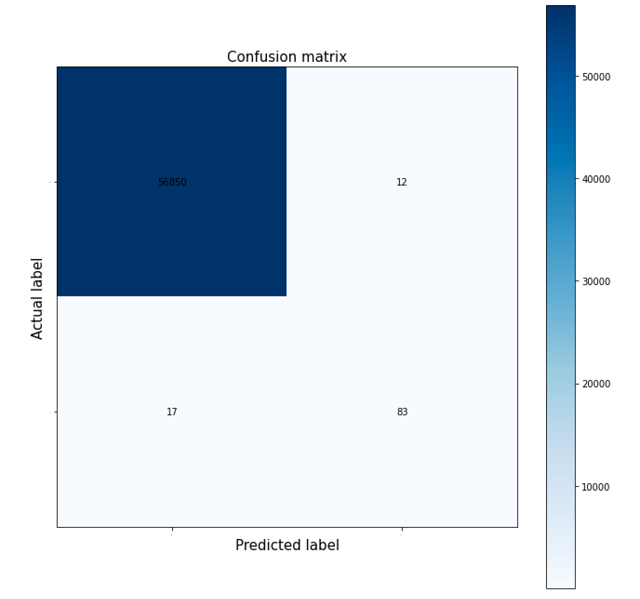
| Accuracy | Recall | Precision | AUC-ROC |
|---|---|---|---|
| 0.99949 | 0.83017658 | 0.8736842 | 0.9148944 |
5.4 SVM
SVM was the largely successful in classifying fraudulent transactions as such, with a recall of around 91% and accuracy of around 99%.
We were able to tune the oversampling ratio (for SMOTE) and type of kernel and optimize the precision with a minority: majority ratio of 0.046 and a linear SVM. As you can see below, the precision increases, peaks at 0.046 and then sharply declines after. We also tried using a non linear sigmoid kernel but our precision dropped a lot and it also took considerably more runtime.
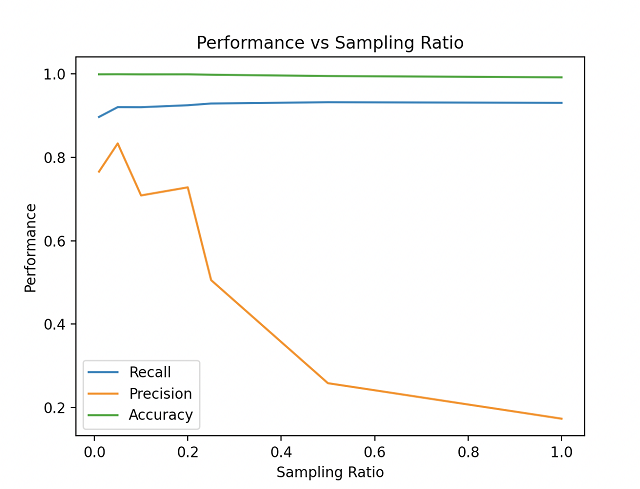
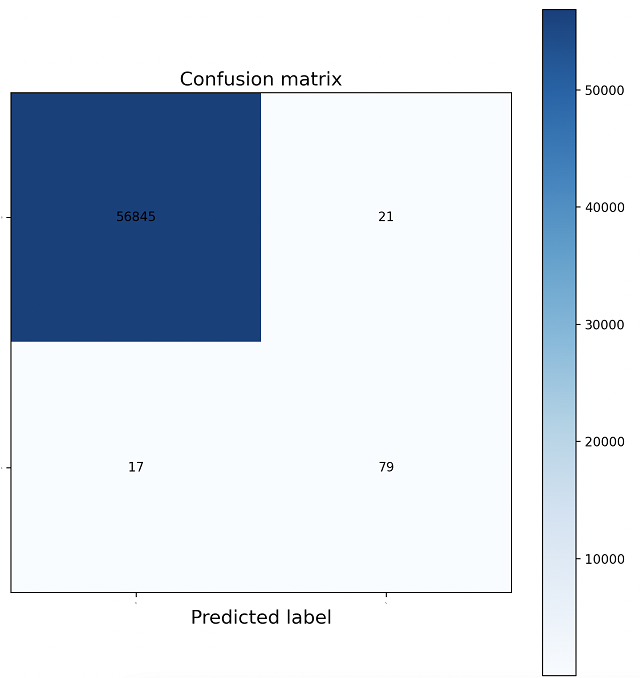
| Accuracy | Recall | Precision | AUC-ROC |
|---|---|---|---|
| 0.999333 | 0.915578 | 0.790000 | 0.911274 |
6 Conclusions
| Model | Accuracy | Recall | Precision | AUC-ROC |
|---|---|---|---|---|
| Logistic w/ Smote | 0.991170 | 0.965630 | 0.771072 | 0.965630 |
| Random Forest w/ Smote | 0.999508 | 0.852941 | 0.870000 | 0.918129 |
| MLP NN w/ Smote | 0.99949 | 0.83017658 | 0.8736842 | 0.9148944 |
| SVM w/ Smote | 0.999333 | 0.915578 | 0.790000 | 0.911274 |
As expected, with an imbalanced dataset such as ours, resampling techniques applied to rebalance training data increased the efficacy of our models, although this pre-processing seemed to largely decrease precision scores - signalling more false positives than without.
We found that Random Forest and our MLP Neural Network, while decently effective, did not perform as well as the Logistic Regression and SVM model. Our SVM model has a higher precision, while the Logistic Regression model outperformed SVM in recall. While the others generally had higher precision ratings than logistic regression, their recall scores left a lot to be desired, with our neural network only barely surpassing a recall of 83%.
Based on our assessment that recall alongside accuracy would be the most relevant parameters in evaluating our models, Logistic Regression appeared to be the most successful model in identifying fraudulent data - especially when paired with SMOTE. Our model had a recall score of .965 while maintaining an accuracy of .992, meaning we only missed around 3% of fraudulent transactions while still classifying the vast majority of datapoints properly.
7 Process Documents
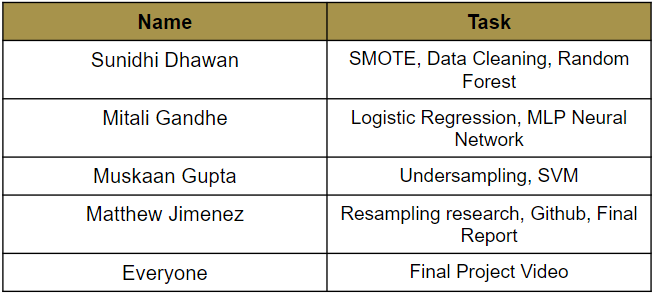
7.1 Contribution Table
7.2 Project Proposal Video
Please visit this link to view the video. You can also visit this link to see our slides!
7.3 Final Project Video
Please visit this link to view the video. You can also visit this link to see our slides!
8 References
Bachmann, J. M., Bhat, N., & Luo. (2021, May 3). Credit Card Fraud Detection.
Draelos, R. (2019, March 2). Measuring Performance: AUPRC and Average Precision [web log]. Retrieved October 7, 2022, from https://glassboxmedicine.com/2019/03/02/measuring-performance-auprc/.
Department of Justice, Federal Trade Commission. 2021, February. Consumer Sentinel Network: Data Book 2020. https://www.ftc.gov/system/files/documents/reports/consumer-sentinel-network-data-book-2020/csn_annual_data_book_2020.pdf
Gomila, R. (2019, July 11). Logistic or linear? Estimating causal effects of experimental treatments on binary outcomes using regression analysis. https://doi.org/10.31234/osf.io/4gmbv
Kulatilleke. (2022). Challenges and Complexities in Machine Learning based Credit Card Fraud Detection. https://doi.org/10.48550/arXiv.2208.10943
Le Borgne, Y., Siblini, W., Lebichot, B., and Bontempi, G. (2022). Reproducible Machine Learning for Credit Card Fraud Detection - Practical Handbook. https://github.com/Fraud-Detection-Handbook/fraud-detection-handbook
Porkess, & Mason, S. (2012). Looking at debit and credit card fraud. Teaching Statistics, 34(3), 87–91. https://doi.org/10.1111/j.1467-9639.2010.00437.x